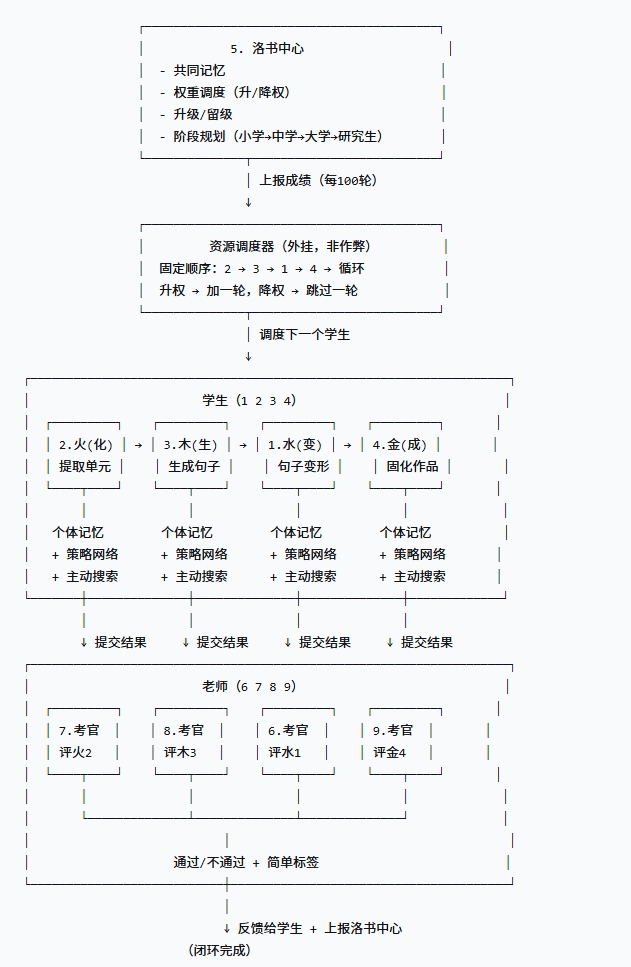
# hetu_luoshu_v4.py - 河图洛书智能体 V4(镜像+圆周率版 + 二八定律)
# 镜像:阴阳五行的数学化(四池架构 + 五行生克)
# 圆周率:道的数学化(活的圆周率计算,永不存储)
# 二八定律:
# 水1: 80%从木池捞主食,20%从火池捞零食
# 金4: 80%从水池捞主食,20%从木池偷零食
import os
import json
import random
import time
import requests
import re
import subprocess
from collections import Counter
from typing import List, Dict, Any, Optional
from urllib.parse import quote
from datetime import datetime
from decimal import Decimal, getcontext
# 尝试导入 gmpy2(真圆周率引擎)
try:
import gmpy2
GMPY2_AVAILABLE = True
except ImportError:
GMPY2_AVAILABLE = False
print("⚠️ gmpy2 未安装,将使用 BBP 引擎(精度有限)")
print(" 建议安装: pip install gmpy2")
# ==================== DeepSeek API 配置 ====================
DEEPSEEK_API_KEY = "sk-952a1c833f61473ca2fe38a1bb367e9e"
DEEPSEEK_API_URL = "https://api.deepseek.com/v1/chat/completions"
_api_fail_count = 0
_api_fail_threshold = 5
def call_deepseek(prompt: str, max_tokens: int = 800, temperature: float = 0.5) -> Optional[str]:
global _api_fail_count
try:
headers = {"Content-Type": "application/json", "Authorization": f"Bearer {DEEPSEEK_API_KEY}"}
data = {"model": "deepseek-chat", "messages": [{"role": "user", "content": prompt}], "max_tokens": max_tokens, "temperature": temperature}
resp = requests.post(DEEPSEEK_API_URL, json=data, headers=headers, timeout=30)
if resp.status_code == 200:
_api_fail_count = 0
return resp.json()["choices"][0]["message"]["content"]
_api_fail_count += 1
return None
except Exception as e:
_api_fail_count += 1
print(f"DeepSeek API 调用失败: {e}")
return None
def is_api_degraded() -> bool:
return _api_fail_count >= _api_fail_threshold
def web_search(keyword: str) -> Optional[str]:
try:
url = f"https://baike.baidu.com/item/{quote(keyword)}"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'}
resp = requests.get(url, headers=headers, timeout=15)
if resp.status_code == 200:
match = re.search(r'<div class="lemma-summary">(.*?)</div>', resp.text, re.DOTALL)
if match:
text = re.sub(r'<[^>]+>', '', match.group(1))
return text[:500]
match = re.search(r'<meta name="description" content="(.*?)"', resp.text)
if match:
return match.group(1)[:500]
return None
except Exception as e:
print(f"网上搜索失败: {e}")
return None
# ==================== 道的圆周率引擎 V3(真圆周率 + 流式) ====================
class DaoPi:
"""
道 V3:真圆周率引擎(基于 gmpy2)
- 不存储完整历史,只缓存当前视野(chunk)
- 指针走完当前 chunk,自动预加载下一段
- 永不枯竭,永不重复
- 完美符合"C + 5位变量"的设计
"""
def __init__(self, chunk_size: int = 5000):
self.chunk_size = chunk_size
self.pointer = 0 # 当前已读取的总位数
self.cache = [] # 当前 chunk 的数字列表
self.current_chunk_start = 0 # 当前 chunk 起始位置
# 根据可用性选择引擎
if GMPY2_AVAILABLE:
self._use_gmpy2 = True
print(f" 📐 道引擎:gmpy2(真圆周率),chunk_size={chunk_size}")
self._load_chunk_gmpy2(0)
else:
self._use_gmpy2 = False
print(f" 📐 道引擎:BBP(备用),chunk_size={chunk_size},精度有限")
self._load_chunk_bbp(0)
def _load_chunk_gmpy2(self, start_pos: int) -> None:
"""使用 gmpy2 加载圆周率段(真圆周率)"""
# 设置精度:需要计算的位数 + 安全余量
precision_bits = (start_pos + self.chunk_size + 100) * 4
gmpy2.get_context().precision = precision_bits
# 获取圆周率
pi = gmpy2.const_pi()
# 转换为字符串,需要指定十进制位数
decimal_places = start_pos + self.chunk_size + 50
pi_str = format(pi, f'.{decimal_places}f')
# 去掉 "3.",只取小数部分
if '.' in pi_str:
pi_str = pi_str.split('.')[1]
else:
pi_str = ""
# 取从 start_pos 开始的 chunk_size 位
if start_pos < len(pi_str):
segment = pi_str[start_pos:start_pos + self.chunk_size]
else:
segment = ""
# 如果长度不够,补足(理论上不会,但安全起见)
while len(segment) < self.chunk_size:
segment += "0"
# 转为整数列表
self.cache = [int(ch) for ch in segment]
self.current_chunk_start = start_pos
print(f" 📐 道已加载新段: 位置 {start_pos} - {start_pos + self.chunk_size}(gmpy2)")
def _load_chunk_bbp(self, start_pos: int) -> None:
"""使用 BBP 公式加载圆周率段(备用方案)"""
# 动态设置精度
need_precision = start_pos + self.chunk_size + 50
getcontext().prec = need_precision + 10
# BBP 公式计算圆周率
pi = Decimal(0)
for k in range(need_precision):
pi += (Decimal(1)/(16**k)) * (
Decimal(4)/(8*k+1) -
Decimal(2)/(8*k+4) -
Decimal(1)/(8*k+5) -
Decimal(1)/(8*k+6)
)
pi_str = str(pi)[2:] # 去掉"3."
# 取需要的段
if start_pos < len(pi_str):
segment = pi_str[start_pos:start_pos + self.chunk_size]
else:
segment = ""
while len(segment) < self.chunk_size:
segment += "0"
self.cache = [int(ch) for ch in segment]
self.current_chunk_start = start_pos
print(f" 📐 道已加载新段: 位置 {start_pos} - {start_pos + self.chunk_size}(BBP)")
def _ensure_cache(self, pos: int) -> None:
"""确保 pos 位置在 cache 中,否则重新加载"""
if pos < self.current_chunk_start or pos >= self.current_chunk_start + self.chunk_size:
# 需要加载新段
if self._use_gmpy2:
self._load_chunk_gmpy2(pos)
else:
self._load_chunk_bbp(pos)
def next_digit(self) -> int:
"""获取下一位"""
self._ensure_cache(self.pointer)
idx = self.pointer - self.current_chunk_start
digit = self.cache[idx]
self.pointer += 1
return digit
def novelty(self, length: int = 8) -> float:
"""获取新奇信号 0-1 之间,取接下来的 length 位"""
segment = ''.join(str(self.next_digit()) for _ in range(length))
numeric = 0
for i, ch in enumerate(segment):
numeric += int(ch) * (0.1 ** (i+1))
novelty = numeric / 0.111111
return min(0.99, novelty)
def get_pointer(self) -> int:
"""当前已读取的位数"""
return self.pointer
def peek(self, n: int = 10) -> str:
"""窥探接下来的 n 位,不移动指针(调试用)"""
old_pointer = self.pointer
digits = []
for _ in range(n):
self._ensure_cache(self.pointer)
idx = self.pointer - self.current_chunk_start
digits.append(str(self.cache[idx]))
self.pointer += 1
self.pointer = old_pointer
return ''.join(digits)
def reset_pointer(self):
"""重置指针(雷霆之怒时用)"""
self.pointer = 0
if self._use_gmpy2:
self._load_chunk_gmpy2(0)
else:
self._load_chunk_bbp(0)
# ==================== 小型策略网络 ====================
class SimpleStrategyNet:
def __init__(self, student_id: str):
self.student_id = student_id
self.experiences = []
def predict(self, recent_memory: List[Dict]) -> Dict[str, float]:
if len(recent_memory) < 3:
return {"curiosity": 0.3, "intensity": 0.5, "variety": 0.5}
recent_scores = [m.get("teacher_score", 0) for m in recent_memory[-3:]]
avg_score = sum(recent_scores) / len(recent_scores) if recent_scores else 0.5
if avg_score > 0.8:
return {"curiosity": 0.2, "intensity": 0.3, "variety": 0.4}
elif avg_score < 0.3:
return {"curiosity": 0.6, "intensity": 0.8, "variety": 0.7}
else:
return {"curiosity": 0.4, "intensity": 0.5, "variety": 0.5}
def update(self, teacher_score: float, last_action: Dict):
self.experiences.append({"time": time.time(), "action": last_action, "score": teacher_score})
if len(self.experiences) > 100:
self.experiences = self.experiences[-100:]
# ==================== 火池(存储火2提取的单元) ====================
class FirePool:
def __init__(self, max_size: int = 2000):
self.max_size = max_size
self.pool = []
self._dirty = True
self._load()
def _get_filename(self) -> str:
return "memories/fire_pool.json"
def _load(self):
filename = self._get_filename()
if os.path.exists(filename):
try:
with open(filename, 'r', encoding='utf-8') as f:
data = json.load(f)
self.pool = data.get("pool", [])
print(f" 🔥 加载火池,{len(self.pool)} 个单元")
except:
pass
def _save(self):
os.makedirs("memories", exist_ok=True)
filename = self._get_filename()
with open(filename, 'w', encoding='utf-8') as f:
json.dump({"pool": self.pool}, f, ensure_ascii=False, indent=2)
def add(self, unit: str, source: str = "火2", frequency: int = 1, quality: float = 0.5):
for existing in self.pool:
if existing["unit"] == unit:
existing["frequency"] += frequency
existing["quality"] = max(existing["quality"], quality)
existing["time"] = time.time()
self._dirty = True
self._save()
return
self.pool.append({
"unit": unit,
"frequency": frequency,
"source": source,
"quality": quality,
"time": time.time()
})
self._dirty = True
if len(self.pool) > self.max_size:
self._ensure_sorted()
self.pool = self.pool[:self.max_size]
self._save()
def _ensure_sorted(self):
if self._dirty:
self.pool.sort(key=lambda x: x["quality"] * (1 + x["frequency"] / 100), reverse=True)
self._dirty = False
def get_best(self, num: int = 100) -> List[str]:
self._ensure_sorted()
return [item["unit"] for item in self.pool[:num]]
def get_random(self, num: int = 20) -> List[str]:
if not self.pool:
return []
random.shuffle(self.pool)
return [item["unit"] for item in self.pool[:num]]
def clean_old(self, max_age_seconds: int = 86400):
now = time.time()
old_count = len(self.pool)
self.pool = [item for item in self.pool if now - item["time"] < max_age_seconds]
if len(self.pool) != old_count:
self._dirty = True
self._save()
# ==================== 木池(存储木3生成的句子) ====================
class WoodPool:
def __init__(self, max_size: int = 500):
self.max_size = max_size
self.pool = []
self._dirty = True
self._load()
def _get_filename(self) -> str:
return "memories/wood_pool.json"
def _load(self):
filename = self._get_filename()
if os.path.exists(filename):
try:
with open(filename, 'r', encoding='utf-8') as f:
data = json.load(f)
self.pool = data.get("pool", [])
print(f" 🌳 加载木池,{len(self.pool)} 条句子")
except:
pass
def _save(self):
os.makedirs("memories", exist_ok=True)
filename = self._get_filename()
with open(filename, 'w', encoding='utf-8') as f:
json.dump({"pool": self.pool}, f, ensure_ascii=False, indent=2)
def add(self, text: str, source: str = "木3", score: float = 0.5):
for existing in self.pool:
if existing["text"] == text:
existing["score"] = max(existing["score"], score)
existing["time"] = time.time()
self._dirty = True
self._save()
return
self.pool.append({
"text": text,
"score": score,
"source": source,
"time": time.time()
})
self._dirty = True
if len(self.pool) > self.max_size:
self._ensure_sorted()
self.pool = self.pool[:self.max_size]
self._save()
def _ensure_sorted(self):
if self._dirty:
self.pool.sort(key=lambda x: x["score"], reverse=True)
self._dirty = False
def get_best(self, min_len: int = 8, max_len: int = 100, num: int = 10) -> List[str]:
self._ensure_sorted()
results = []
for item in self.pool:
text = item["text"]
if min_len <= len(text) <= max_len:
results.append(text)
if len(results) >= num:
break
return results
def get_random(self, num: int = 5) -> List[str]:
if not self.pool:
return []
random.shuffle(self.pool)
return [item["text"] for item in self.pool[:num]]
def update_score(self, text: str, score: float):
for item in self.pool:
if item["text"] == text:
item["score"] = score
self._dirty = True
break
self._save()
def clean_old(self, max_age_seconds: int = 3600):
now = time.time()
old_count = len(self.pool)
self.pool = [item for item in self.pool if now - item["time"] < max_age_seconds]
if len(self.pool) != old_count:
self._dirty = True
self._save()
# ==================== 水池(存储水1产生的变体) ====================
class WaterPool:
def __init__(self, max_size: int = 200):
self.max_size = max_size
self.pool = []
self._dirty = True
self._load()
def _get_filename(self) -> str:
return "memories/water_pool.json"
def _load(self):
filename = self._get_filename()
if os.path.exists(filename):
try:
with open(filename, 'r', encoding='utf-8') as f:
data = json.load(f)
self.pool = data.get("pool", [])
print(f" 💧 加载水池,{len(self.pool)} 条变体")
except:
pass
def _save(self):
os.makedirs("memories", exist_ok=True)
filename = self._get_filename()
with open(filename, 'w', encoding='utf-8') as f:
json.dump({"pool": self.pool}, f, ensure_ascii=False, indent=2)
def add(self, text: str, source: str = "水1", score: float = 0.5):
for existing in self.pool:
if existing["text"] == text:
existing["score"] = max(existing["score"], score)
existing["time"] = time.time()
self._dirty = True
self._save()
return
self.pool.append({
"text": text,
"score": score,
"source": source,
"time": time.time()
})
self._dirty = True
if len(self.pool) > self.max_size:
self._ensure_sorted()
self.pool = self.pool[:self.max_size]
self._save()
def _ensure_sorted(self):
if self._dirty:
self.pool.sort(key=lambda x: x["score"], reverse=True)
self._dirty = False
def get_best(self, min_len: int = 12, max_len: int = 100, exclude: set = None, num: int = 1) -> List[str]:
"""获取最好的变体,支持返回多个(num参数)"""
self._ensure_sorted()
if exclude is None:
exclude = set()
now = time.time()
scored_items = []
for item in self.pool:
age = now - item["time"]
freshness = max(0.3, 1.0 - age / 7200)
effective_score = item["score"] * freshness
scored_items.append((effective_score, item))
scored_items.sort(reverse=True, key=lambda x: x[0])
results = []
for effective_score, item in scored_items:
text = item["text"]
if min_len <= len(text) <= max_len and text not in exclude:
if any('\u4e00' <= c <= '\u9fff' for c in text):
results.append(text)
if len(results) >= num:
break
return results
def update_score(self, text: str, score: float):
for item in self.pool:
if item["text"] == text:
item["score"] = score
self._dirty = True
break
self._save()
def clean_old(self, max_age_seconds: int = 3600):
now = time.time()
old_count = len(self.pool)
self.pool = [item for item in self.pool if now - item["time"] < max_age_seconds]
if len(self.pool) != old_count:
self._dirty = True
self._save()
def get_stats(self) -> dict:
return {"size": len(self.pool), "max_size": self.max_size}
# ==================== 同义词自学习模块 ====================
class SynonymLearner:
def __init__(self):
self.synonyms = {}
self.cooccurrence = Counter()
self._load()
self._init_fallback()
def _init_fallback(self):
self._fallback = {
"好": ["棒", "优", "佳", "美"],
"大": ["巨", "宏", "浩", "庞"],
"小": ["微", "细", "精", "纤"],
"是": ["乃", "即", "为", "系"],
"有": ["具", "含", "拥", "备"],
"无": ["缺", "失", "乏", "没"],
"多": ["众", "繁", "丰", "盛"],
"少": ["稀", "寡", "微", "欠"],
"美": ["丽", "艳", "秀", "雅"],
"真": ["实", "诚", "确", "正"],
}
def _get_filename(self) -> str:
return "memories/synonyms_memory.json"
def _load(self):
filename = self._get_filename()
if os.path.exists(filename):
try:
with open(filename, 'r', encoding='utf-8') as f:
data = json.load(f)
self.synonyms = data.get("synonyms", {})
self.cooccurrence = Counter(data.get("cooccurrence", {}))
print(f" 📖 加载同义词库,{len(self.synonyms)} 组")
except:
pass
def _save(self):
os.makedirs("memories", exist_ok=True)
filename = self._get_filename()
with open(filename, 'w', encoding='utf-8') as f:
json.dump({
"synonyms": self.synonyms,
"cooccurrence": dict(self.cooccurrence)
}, f, ensure_ascii=False, indent=2)
def learn_from_corpus(self, texts: List[str]):
for text in texts:
words = re.findall(r'[\u4e00-\u9fff]{2,4}', text)
for i, w1 in enumerate(words):
for w2 in words[i+1:i+3]:
if w1 != w2:
self.cooccurrence[f"{w1}|{w2}"] += 1
self.cooccurrence[f"{w2}|{w1}"] += 1
threshold = 3
for pair, count in self.cooccurrence.items():
if count >= threshold:
w1, w2 = pair.split('|')
if w1 not in self.synonyms:
self.synonyms[w1] = []
if w2 not in self.synonyms[w1]:
self.synonyms[w1].append(w2)
if w2 not in self.synonyms:
self.synonyms[w2] = []
if w1 not in self.synonyms[w2]:
self.synonyms[w2].append(w1)
self._save()
print(f" 📚 同义词学习完成,现有 {len(self.synonyms)} 组")
def get(self, word: str) -> List[str]:
if word in self.synonyms and self.synonyms[word]:
return self.synonyms[word]
return self._fallback.get(word, [])
# ==================== 学生基类 ====================
class Student:
def __init__(self, student_id: str, name: str):
self.id = student_id
self.name = name
self.memory = []
self.learning_memory = []
self.strategy_net = SimpleStrategyNet(student_id)
self.skill_level = 0.3
self.blocked = False
self.learning_rounds = 0
self.consecutive_passes = 0
self.is_graduated = False
self.luoshu = None
self.can_think = False
self._load_individual_memory()
def _get_memory_filename(self) -> str:
name_map = {
"火2-化": "huo2_memory",
"木3-生": "mu3_memory",
"水1-变": "shui1_memory",
"金4-成": "jin4_memory"
}
base = name_map.get(self.name, self.name.replace("-", "_"))
return f"memories/{base}.json"
def _atomic_write(self, filename: str, data: dict):
tmp_filename = filename + ".tmp"
with open(tmp_filename, 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=2)
os.replace(tmp_filename, filename)
def _load_individual_memory(self):
filename = self._get_memory_filename()
if os.path.exists(filename):
try:
with open(filename, 'r', encoding='utf-8') as f:
data = json.load(f)
self.memory = data.get("memory", [])
self.learning_memory = data.get("learning_memory", [])
self.skill_level = data.get("skill_level", 0.3)
self.blocked = data.get("blocked", False)
self.learning_rounds = data.get("learning_rounds", 0)
self.consecutive_passes = data.get("consecutive_passes", 0)
self.is_graduated = data.get("is_graduated", False)
if hasattr(self, "works"):
self.works = data.get("works", [])
print(f" 📂 [{self.name}] 加载记忆,技能={self.skill_level:.2f}, 阻塞={self.blocked}")
except Exception as e:
print(f" ⚠️ [{self.name}] 加载记忆失败: {e}")
def _save_individual_memory(self):
os.makedirs("memories", exist_ok=True)
filename = self._get_memory_filename()
data = {
"name": self.name,
"memory": self.memory[-200:],
"learning_memory": self.learning_memory[-50:],
"skill_level": self.skill_level,
"blocked": self.blocked,
"learning_rounds": self.learning_rounds,
"consecutive_passes": self.consecutive_passes,
"is_graduated": self.is_graduated,
}
if hasattr(self, "works"):
data["works"] = self.works
self._atomic_write(filename, data)
def _search_web(self, query: str) -> Optional[str]:
print(f" 🌐 [{self.name}] 网上搜索: {query[:50]}...")
return web_search(query)
def _search_api(self, query: str) -> Optional[str]:
print(f" 🤖 [{self.name}] API搜索: {query[:50]}...")
return call_deepseek(f"请提供关于「{query}」的中文百科信息,200字以内。只返回客观事实。", max_tokens=500, temperature=0.3)
def _get_masterpiece_from_common(self) -> Optional[str]:
if self.luoshu:
masterpieces = self.luoshu.common_memory.get("masterpieces", [])
if masterpieces:
return random.choice(masterpieces).get("text", "")
return None
def _learn_from_sources(self, topic: str):
print(f" 📚 [{self.name}] 开始学习: {topic[:50]}...")
web_result = self._search_web(topic)
time.sleep(0.3)
api_result = self._search_api(topic)
time.sleep(0.3)
masterpiece = self._get_masterpiece_from_common()
self.learning_memory.append({"time": time.time(), "topic": topic, "web": web_result[:200] if web_result else "", "api": api_result[:200] if api_result else ""})
self.skill_level = min(1.0, self.skill_level + 0.1)
self._save_individual_memory()
print(f" 📈 [{self.name}] 技能等级: {self.skill_level:.2f}")
def learn(self, topic: str):
self.learning_rounds += 1
print(f" 📚 [{self.name}] 学习轮次: {self.learning_rounds}/3")
self._learn_from_sources(topic)
def on_pass(self):
self.consecutive_passes += 1
self._save_individual_memory()
print(f" ✅ [{self.name}] 通过 ({self.consecutive_passes}/3)")
if self.consecutive_passes >= 3:
self.is_graduated = True
print(f" 🎉 [{self.name}] 毕业!")
def on_fail(self, fail_reason: str = ""):
self.consecutive_passes = 0
self.is_graduated = False
self.blocked = True
self.learning_rounds = 0
self._save_individual_memory()
print(f" ❌ [{self.name}] 不通过,进入学习模式(需学习3轮)")
def can_retry(self) -> bool:
if not self.blocked:
return True
if self.learning_rounds >= 3:
self.blocked = False
self.learning_rounds = 0
self._save_individual_memory()
print(f" 🔓 [{self.name}] 学习完成,开始重做")
return True
return False
def receive_feedback(self, teacher_score: float, teacher_comment: str = ""):
self.memory.append({"time": time.time(), "score": teacher_score, "comment": teacher_comment})
self.strategy_net.update(teacher_score, {})
if len(self.memory) > 200:
self.memory = self.memory[-200:]
self._save_individual_memory()
def _get_mimic_ratio(self) -> float:
base_ratio = 0.20
skill_penalty = self.skill_level * 0.1
return max(0.10, min(0.30, base_ratio - skill_penalty))
def _get_dao_effect(self) -> float:
if self.luoshu and hasattr(self.luoshu, 'dao_novelty'):
return self.luoshu.dao_novelty
return 0.5
def _maybe_mimic(self, original_output: Dict, context: Dict) -> Dict:
mimic_ratio = self._get_mimic_ratio()
if random.random() >= mimic_ratio:
return original_output
print(f"🎭 [{self.name}] 触发模仿模式 (比例={mimic_ratio:.0%})...")
if self.luoshu is None:
return original_output
if "火2" in self.name:
masterpieces = self.luoshu.common_memory.get("masterpieces", [])
if masterpieces:
all_words = []
for mp in masterpieces[-10:]:
text = mp.get("text", "")
words = re.findall(r'[\u4e00-\u9fff]{2,4}', text)
all_words.extend(words)
if all_words:
word_counter = Counter(all_words)
top_words = [w for w, c in word_counter.most_common(5)]
current_units = original_output.get("units", [])
new_units = list(set(current_units + top_words))
original_output["units"] = new_units
print(f"🔥 [火2] 模仿了优秀词汇: {top_words[:3]}")
else:
premium_words = ["系统", "智能", "演化", "涌现", "结构", "认知", "河图", "洛书"]
current_units = original_output.get("units", [])
new_units = list(set(current_units + premium_words[:3]))
original_output["units"] = new_units
print(f"🔥 [火2] 模仿了预设词汇: {premium_words[:3]}")
elif "木3" in self.name:
masterpieces = self.luoshu.common_memory.get("masterpieces", [])
if masterpieces:
sample = random.choice(masterpieces[-10:])
sample_text = sample.get("text", "")
sentences = re.findall(r'[^。!?;]*[。!?;]', sample_text)
if sentences:
template = sentences[0]
punctuation = re.findall(r'[,。!?;、]', template)
if punctuation:
sentence = original_output.get("sentence", "")
if sentence:
connectors = ["因为", "所以", "但是", "然而", "于是", "因此"]
prefix = random.choice(connectors)
original_output["sentence"] = f"{prefix}{sentence}"
print(f"🌳 [木3] 模仿了句式逻辑: {prefix}...")
else:
sentence = original_output.get("sentence", "")
if sentence:
original_output["sentence"] = f"{sentence}。"
print(f"🌳 [木3] 模仿了句号结尾")
else:
sentence = original_output.get("sentence", "")
if sentence and len(sentence) < 20:
connectors = ["因为", "所以", "但是", "然而"]
prefix = random.choice(connectors)
original_output["sentence"] = f"{prefix}{sentence}"
print(f"🌳 [木3] 模仿了逻辑连接词: {prefix}")
elif "水1" in self.name:
sentence = original_output.get("sentence", "")
if sentence and len(sentence) > 5:
techniques = [
("加修辞前缀", lambda s: f"堪称完美的{s}" if len(s) < 30 else f"令人惊叹的{s}"),
("加反问语气", lambda s: f"难道{s}不是真理吗?"),
("加排比结构", lambda s: f"不仅{s},而且{s},更是{s}"[:100]),
("加夸张表达", lambda s: f"毫无疑问,{s}"),
("加古风表达", lambda s: f"夫{s},诚然也。"),
]
tech_name, tech_func = random.choice(techniques)
new_sentence = tech_func(sentence)
original_output["sentence"] = new_sentence
print(f"💧 [水1] 模仿了修辞: {tech_name}")
elif "金4" in self.name:
masterpieces = self.luoshu.common_memory.get("masterpieces", [])
if masterpieces:
best = max(masterpieces, key=lambda x: len(x.get("text", "")))
old_text = best.get("text", "")
if old_text and len(old_text) > 10:
new_text = old_text
if self.luoshu and hasattr(self.luoshu, 'synonym_learner'):
words = re.findall(r'[\u4e00-\u9fff]{2,4}', new_text)
for word in words:
synonyms = self.luoshu.synonym_learner.get(word)
if synonyms and random.random() < 0.3:
new_text = new_text.replace(word, random.choice(synonyms), 1)
if new_text and new_text[-1] in "。!?":
new_text = new_text[:-1] + random.choice("。!?")
original_output["final"] = new_text
print(f"🏆 [金4] 模仿了满分作文并微调")
else:
templates = [
"天地之间,万物演化,河图洛书,揭示其理。",
"智能之形,源于结构,涌现于交互,成就于演化。",
"阴阳相生,五行相克,八卦相荡,万物相成。",
]
original_output["final"] = random.choice(templates)
print(f"🏆 [金4] 模仿了预设模板")
return original_output
def _try_think(self, context: Dict) -> Optional[Dict]:
return None
def execute(self, context: Dict = None) -> Dict:
if context is None:
context = {}
thinking_result = self._try_think(context)
if thinking_result and thinking_result.get("valid"):
print(f" 🧠 [{self.name}] 思考成功")
return thinking_result["output"]
print(f" ⚙️ [{self.name}] 使用规则")
output = self._rule_based_execute(context)
final_output = self._maybe_mimic(output, context)
return final_output
def _rule_based_execute(self, context: Dict) -> Dict:
raise NotImplementedError
# ==================== 老师基类 ====================
class Teacher:
def __init__(self, teacher_id: str, student_name: str):
self.id = teacher_id
self.student_name = student_name
self.records = []
self.pass_threshold = 0.6
self.evolution_advice = ""
self.rule_description = self._get_default_rule()
self.luoshu = None
self.api_fail_count = 0
self.use_fallback = False
self._load_individual_memory()
def _get_memory_filename(self) -> str:
return f"memories/teacher_{self.id}_memory.json"
def _get_standard_filename(self) -> str:
return f"standards/teacher_{self.id}_standard.json"
def _atomic_write(self, filename: str, data: dict):
tmp_filename = filename + ".tmp"
with open(tmp_filename, 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=2)
os.replace(tmp_filename, filename)
def _load_individual_memory(self):
os.makedirs("memories", exist_ok=True)
filename = self._get_memory_filename()
if os.path.exists(filename):
try:
with open(filename, 'r', encoding='utf-8') as f:
data = json.load(f)
self.records = data.get("records", [])
self.pass_threshold = data.get("pass_threshold", 0.6)
self.rule_description = data.get("rule_description", self.rule_description)
print(f" 📂 老师{self.id} 加载记忆,{len(self.records)} 条记录")
except Exception as e:
print(f" ⚠️ 老师{self.id} 加载记忆失败: {e}")
def _save_individual_memory(self):
os.makedirs("memories", exist_ok=True)
filename = self._get_memory_filename()
data = {
"teacher_id": self.id,
"student": self.student_name,
"records": self.records[-500:],
"pass_threshold": self.pass_threshold,
"rule_description": self.rule_description,
}
self._atomic_write(filename, data)
def _get_default_rule(self) -> str:
rules = {
"7": "检查提取单元数量:大于50个为丰富,20-50为合适,小于20为不足",
"8": "检查句子:长度大于10且含标点为通顺,长度大于5为合适,否则太短。同时关注意境和文采。",
"6": "检查变体:生成2个以上不同变体为有效,1个为一般,0个为无效",
"9": "检查作品:长度大于10且含中文为合格。优先看句子是否有完整语义和逻辑连贯性。"
}
return rules.get(self.id, "根据学生输出判断是否通过")
def _save_standard(self, current_round: int):
os.makedirs("standards", exist_ok=True)
filename = self._get_standard_filename()
data = {
"teacher_id": self.id,
"student": self.student_name,
"timestamp": datetime.now().isoformat(),
"round": current_round,
"rule_description": self.rule_description,
"pass_threshold": self.pass_threshold,
"evolution_advice": self.evolution_advice,
"recent_pass_rate": self._get_recent_pass_rate(),
"use_fallback": self.use_fallback
}
history = []
if os.path.exists(filename):
try:
with open(filename, 'r', encoding='utf-8') as f:
history = json.load(f)
if isinstance(history, dict):
history = [history]
except:
pass
history.append(data)
if len(history) > 20:
history = history[-20:]
tmp_filename = filename + ".tmp"
with open(tmp_filename, 'w', encoding='utf-8') as f:
json.dump(history, f, ensure_ascii=False, indent=2)
os.replace(tmp_filename, filename)
txt_filename = f"standards/teacher_{self.id}_standard.txt"
with open(txt_filename, 'w', encoding='utf-8') as f:
f.write(f"老师{self.id}({self.student_name})评判标准\n")
f.write(f"更新时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}\n")
f.write(f"当前轮数: {current_round}\n")
f.write(f"通过阈值: {self.pass_threshold}\n")
f.write(f"最近通过率: {self._get_recent_pass_rate():.1%}\n")
f.write(f"降级模式: {'是' if self.use_fallback else '否'}\n")
f.write("-" * 40 + "\n")
f.write(f"评判规则:\n{self.rule_description}\n")
f.write("-" * 40 + "\n")
f.write(f"进化建议:\n{self.evolution_advice}\n")
def _get_recent_pass_rate(self) -> float:
if len(self.records) < 20:
return 0.5
recent = self.records[-50:]
return sum(1 for r in recent if r.get("passed", False)) / len(recent)
def _get_dao_effect(self) -> float:
if self.luoshu and hasattr(self.luoshu, 'dao_novelty'):
return (self.luoshu.dao_novelty - 0.5) * 0.2
return 0.0
def evaluate(self, student_output: Dict) -> tuple:
score = 0.5
comment = ""
dao_effect = self._get_dao_effect()
if self.id == "7":
units = student_output.get("units", [])
if len(units) > 50:
score = 0.9 + dao_effect
comment = "提取丰富"
elif len(units) > 20:
score = 0.7 + dao_effect
comment = "提取合适"
else:
score = 0.4 + dao_effect
comment = "提取不足"
elif self.id == "8":
sentence = student_output.get("sentence", "")
if len(sentence) > 15 and any(p in sentence for p in "。!?;"):
score = 0.9 + dao_effect
comment = "句子通顺"
elif len(sentence) > 8:
score = 0.7 + dao_effect
comment = "句子长度合适"
else:
score = 0.3 + dao_effect
comment = "句子太短"
elif self.id == "6":
variants = student_output.get("variants", [])
unique_variants = len(set(variants))
if unique_variants >= 2:
score = 0.8 + dao_effect
comment = f"生成{unique_variants}个有效变体"
elif unique_variants == 1:
score = 0.5 + dao_effect
comment = "只生成1个变体"
else:
score = 0.3 + dao_effect
comment = "生成0个变体"
if self.luoshu and hasattr(self.luoshu, 'water_pool'):
for v in variants:
v_score = min(1.0, len(v) / 50)
self.luoshu.water_pool.update_score(v, v_score)
elif self.id == "9":
final = student_output.get("final", "")
if self.use_fallback:
if final and len(final) > 10:
score = 0.85 + dao_effect
comment = "作品合格(降级模式)"
else:
score = 0.2 + dao_effect
comment = "无作品"
else:
if final and len(final) > 10:
if any(kw in final for kw in ["故", "然", "所以", "因此", "则"]):
score = 0.95 + dao_effect
comment = "作品合格且有逻辑"
else:
score = 0.85 + dao_effect
comment = "作品合格"
else:
score = 0.2 + dao_effect
comment = "无作品"
score = max(0.0, min(1.0, score))
passed = score >= 0.6
self.records.append({
"time": time.time(),
"student_output": str(student_output)[:100],
"score": score,
"passed": passed,
"comment": comment
})
if len(self.records) > 500:
self.records = self.records[-500:]
self._save_individual_memory()
return passed, score, comment
def self_evolve(self, current_round: int):
if self.use_fallback:
print(f" ⏸️ 老师{self.id} 处于降级模式,跳过进化")
return
if len(self.records) < 10:
print(f" ⏭️ 老师{self.id} 记录不足10条,跳过进化")
return
recent_records = self.records[-30:]
pass_rate = sum(1 for r in recent_records if r.get("passed", False)) / len(recent_records) if recent_records else 0.5
passed_examples = [r.get("student_output", "")[:80] for r in recent_records if r.get("passed", False)][-2:]
failed_examples = [r.get("student_output", "")[:80] for r in recent_records if not r.get("passed", False)][-2:]
prompt = f"""你是老师{self.id},负责评判{self.student_name}。
当前规则:{self.rule_description}
最近30次评判通过率:{pass_rate:.1%}
通过示例:{passed_examples}
未通过示例:{failed_examples}
请给出改进建议。不要只看长度和数量,要关注意境的连贯性、逻辑的完整性、表达的自然度。一句话即可。
"""
print(f" 📖 老师{self.id} 开始自我进化...")
response = call_deepseek(prompt, max_tokens=200, temperature=0.6)
if response:
self.api_fail_count = 0
self.evolution_advice = response
self.rule_description = response[:300]
print(f" ✅ 老师{self.id} 进化完成: {self.rule_description[:80]}...")
else:
self.api_fail_count += 1
print(f" ⚠️ 老师{self.id} API无返回,连续失败 {self.api_fail_count} 次")
if self.api_fail_count >= 3:
self.use_fallback = True
print(f" 🔻 老师{self.id} 进入降级模式")
self._save_standard(current_round)
self._save_individual_memory()
def try_recover(self):
if not self.use_fallback:
return
test_response = call_deepseek("回复'OK'", max_tokens=5, temperature=0)
if test_response:
self.use_fallback = False
self.api_fail_count = 0
print(f" 🔺 老师{self.id} 已恢复,退出降级模式")
return True
return False
# ==================== 洛书中心 ====================
class LuoShuCenter:
def __init__(self):
self.common_memory = {"masterpieces": [], "stats": {}, "stage": "小学", "weights": {"火2": 1.0, "木3": 1.0, "水1": 1.0, "金4": 1.0}}
self.evolution_advice = ""
self.quality_rule = "长度大于10且含中文,优先看语义连贯性"
self.memory = []
self.stage_start_round = 0
self.min_rounds_per_stage = 500
self.synonym_learner = SynonymLearner()
self.fire_pool = FirePool(max_size=2000)
self.wood_pool = WoodPool(max_size=500)
self.water_pool = WaterPool(max_size=200)
# 道的圆周率引擎 V3(真圆周率 + 流式)
self.dao = DaoPi(chunk_size=5000)
self.dao_novelty = 0.5
self._load_individual_memory()
self._load_standard()
def _atomic_write(self, filename: str, data: dict):
tmp_filename = filename + ".tmp"
with open(tmp_filename, 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=2)
os.replace(tmp_filename, filename)
def _get_memory_filename(self) -> str:
return "memories/luoshu_center_memory.json"
def _get_standard_filename(self) -> str:
return "standards/luoshu_center_standard.json"
def _load_individual_memory(self):
os.makedirs("memories", exist_ok=True)
filename = self._get_memory_filename()
if os.path.exists(filename):
try:
with open(filename, 'r', encoding='utf-8') as f:
data = json.load(f)
self.memory = data.get("memory", [])
self.common_memory = data.get("common_memory", self.common_memory)
print(f"📂 洛书中心加载记忆,{len(self.memory)} 条记录")
except Exception as e:
print(f"⚠️ 洛书中心加载记忆失败: {e}")
def _save_individual_memory(self):
os.makedirs("memories", exist_ok=True)
filename = self._get_memory_filename()
data = {
"memory": self.memory[-200:],
"common_memory": self.common_memory,
}
self._atomic_write(filename, data)
def _load_standard(self):
filename = self._get_standard_filename()
if os.path.exists(filename):
try:
with open(filename, 'r', encoding='utf-8') as f:
data = json.load(f)
if isinstance(data, list) and len(data) > 0:
latest = data[-1]
self.quality_rule = latest.get("quality_rule", self.quality_rule)
self.common_memory["stage"] = latest.get("stage", "小学")
self.common_memory["weights"] = latest.get("weights", self.common_memory["weights"])
self.stage_start_round = latest.get("stage_start_round", 0)
print(f"📊 洛书中心加载标准: {self.quality_rule[:50]}...")
except Exception as e:
print(f"⚠️ 洛书中心加载标准失败: {e}")
def _save_standard(self, system):
os.makedirs("standards", exist_ok=True)
filename = self._get_standard_filename()
data = {
"timestamp": datetime.now().isoformat(),
"round": system.round,
"stage": self.common_memory["stage"],
"weights": self.common_memory["weights"],
"quality_rule": self.quality_rule,
"evolution_advice": self.evolution_advice,
"stats": self.common_memory["stats"],
"stage_start_round": self.stage_start_round,
"min_rounds_per_stage": self.min_rounds_per_stage,
"dao_pointer": self.dao.get_pointer()
}
history = []
if os.path.exists(filename):
try:
with open(filename, 'r', encoding='utf-8') as f:
history = json.load(f)
if isinstance(history, dict):
history = [history]
except:
pass
history.append(data)
if len(history) > 20:
history = history[-20:]
tmp_filename = filename + ".tmp"
with open(tmp_filename, 'w', encoding='utf-8') as f:
json.dump(history, f, ensure_ascii=False, indent=2)
os.replace(tmp_filename, filename)
txt_filename = f"standards/luoshu_center_standard.txt"
with open(txt_filename, 'w', encoding='utf-8') as f:
f.write(f"洛书中心(校长)调控标准\n")
f.write(f"更新时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}\n")
f.write(f"当前轮数: {system.round}\n")
f.write(f"当前阶段: {self.common_memory['stage']}\n")
f.write(f"阶段开始轮数: {self.stage_start_round}\n")
f.write(f"各部权重: {self.common_memory['weights']}\n")
f.write(f"道指针位置: {self.dao.get_pointer()}\n")
f.write("-" * 40 + "\n")
f.write(f"作品质量规则:\n{self.quality_rule}\n")
f.write("-" * 40 + "\n")
f.write(f"进化建议:\n{self.evolution_advice}\n")
def report(self, student_id: str, score: float, passed: bool):
if student_id not in self.common_memory["stats"]:
self.common_memory["stats"][student_id] = {"scores": [], "pass_count": 0, "total_count": 0}
self.common_memory["stats"][student_id]["scores"].append(score)
self.common_memory["stats"][student_id]["total_count"] += 1
if passed:
self.common_memory["stats"][student_id]["pass_count"] += 1
if len(self.common_memory["stats"][student_id]["scores"]) > 100:
self.common_memory["stats"][student_id]["scores"] = self.common_memory["stats"][student_id]["scores"][-100:]
self._save_individual_memory()
def add_masterpiece(self, text: str, source: str):
for existing in self.common_memory["masterpieces"][-50:]:
if existing.get("text", "") == text:
return
self.common_memory["masterpieces"].append({"text": text, "source": source, "time": time.time()})
if len(self.common_memory["masterpieces"]) > 100:
self.common_memory["masterpieces"] = self.common_memory["masterpieces"][-100:]
self._save_individual_memory()
def evaluate_works_quality(self, works: List[str]) -> float:
if not works:
return 5.0
works_text = "\n".join([f"{i+1}. {w[:100]}" for i, w in enumerate(works[-5:])])
prompt = f"评价以下作品质量,0-10分,10分最高。优先看语义连贯性和逻辑完整性。只输出平均分。\n{works_text}"
response = call_deepseek(prompt, max_tokens=50, temperature=0.3)
if response:
try:
score = float(re.search(r'(\d+(?:\.\d+)?)', response).group(1))
return min(10, max(0, score))
except:
pass
return 5.0
def self_evolve(self, system):
self.dao_novelty = self.dao.novelty(6)
recent_works = system.jin4.works[-10:] if system.jin4.works else []
work_quality = self.evaluate_works_quality(recent_works)
adjusted_quality = work_quality * (0.8 + self.dao_novelty * 0.4)
self.quality_rule = f"基于第{system.round}轮金4作品质量({adjusted_quality:.1f}/10)自动调整,道新奇度:{self.dao_novelty:.2f}"
self.evolution_advice = f"洛书中心根据金4作品质量({adjusted_quality:.1f}/10)及道信号({self.dao_novelty:.2f})动态调整"
self._save_standard(system)
self._save_individual_memory()
print(f" 📊 洛书中心标准已保存 (质量={adjusted_quality:.1f}, 道新奇={self.dao_novelty:.2f}, 道已算{self.dao.get_pointer()}位)")
if system.round % 500 == 0 and system.round > 0:
texts = [mp.get("text", "") for mp in self.common_memory["masterpieces"][-50:]]
if texts:
self.synonym_learner.learn_from_corpus(texts)
print(f" 📚 同义词库已更新,共 {len(self.synonym_learner.synonyms)} 组")
if system.round % 100 == 0:
self.water_pool.clean_old(max_age_seconds=3600)
self.wood_pool.clean_old()
self.fire_pool.clean_old()
def _check_corpus_requirement(self, system, current_stage: str) -> bool:
if current_stage == "小学":
target_size = int(system.corpus_reader.get_total_text_size() * 0.9)
grown_size = system.get_crawler_size()
return system.corpus_reader.has_scanned_all_files and grown_size >= target_size
elif current_stage == "中学":
target_size = system.corpus_reader.get_total_text_size() * 3
grown_size = system.get_crawler_size()
return grown_size >= target_size
elif current_stage == "大学":
target_size = system.corpus_reader.get_total_text_size() * 9
grown_size = system.get_crawler_size()
return grown_size >= target_size
return False
def get_pool_stats(self) -> dict:
return {
"fire_pool": {"size": len(self.fire_pool.pool), "max": self.fire_pool.max_size},
"wood_pool": {"size": len(self.wood_pool.pool), "max": self.wood_pool.max_size},
"water_pool": {"size": len(self.water_pool.pool), "max": self.water_pool.max_size},
"masterpieces": len(self.common_memory["masterpieces"]),
"dao_pointer": self.dao.get_pointer()
}
def refresh_fire_pool_from_corpus(self, system):
all_chars = system.corpus_reader.all_chars
if all_chars:
self.fire_pool.pool = []
freq = Counter(all_chars)
for ch, cnt in freq.most_common(2000):
self.fire_pool.add(ch, source="语料", frequency=cnt, quality=0.5)
print(f" 🔥 火池已从语料精华池刷新,共 {len(self.fire_pool.pool)} 个单元")
def update_weights_and_stage(self, system):
for student_id, weight in self.common_memory["weights"].items():
stat = self.common_memory["stats"].get(student_id, {"pass_count": 0, "total_count": 1})
pass_rate = stat["pass_count"] / max(1, stat["total_count"])
if pass_rate > 0.8:
self.common_memory["weights"][student_id] = max(0.5, weight * 0.9)
elif pass_rate < 0.3:
self.common_memory["weights"][student_id] = min(2.0, weight * 1.2)
all_pass = all(
self.common_memory["stats"].get(sid, {"pass_count": 0, "total_count": 1}).get("pass_count", 0) /
max(1, self.common_memory["stats"].get(sid, {"total_count": 1}).get("total_count", 1)) > 0.7
for sid in ["火2", "木3", "水1", "金4"]
)
if not all_pass:
return
if self.stage_start_round == 0:
self.stage_start_round = system.round
rounds_in_stage = system.round - self.stage_start_round
if rounds_in_stage < self.min_rounds_per_stage:
print(f"\n📚 四部已合格,但仍在当前阶段磨练中({rounds_in_stage}/{self.min_rounds_per_stage}轮)")
return
current_stage = self.common_memory["stage"]
stages_order = ["小学", "中学", "大学", "研究生"]
current_idx = stages_order.index(current_stage)
if current_idx >= len(stages_order) - 1:
return
if self._check_corpus_requirement(system, current_stage):
self.common_memory["stage"] = stages_order[current_idx + 1]
self.stage_start_round = system.round
print(f"\n🎉 洛书中心:全体毕业!语料达标!升入{stages_order[current_idx + 1]}阶段!")
print(f" 投喂语料: {system.corpus_reader.get_total_text_size()} 字节")
print(f" 自取语料: {system.get_crawler_size()} 字节")
else:
target_size = int(system.corpus_reader.get_total_text_size() * (0.9 if current_stage == "小学" else (3 if current_stage == "中学" else 9)))
print(f"\n📚 四部已合格,但语料不足,暂不升级")
print(f" 需自取语料: {system.get_crawler_size()}/{target_size} 字节")
self._save_individual_memory()
def get_dao_effect(self) -> float:
return (self.dao_novelty - 0.5) * 0.3
# ==================== 语料读取器 ====================
class CorpusReader:
def __init__(self, target_dirs: List[str]):
self.target_dirs = target_dirs
self.total_files = 0
self.scanned_count = 0
self.has_scanned_all_files = False
self.all_chars = []
self.sentence_pool = []
self._build_pools()
def _read_file_with_fallback(self, file_path: str, max_chars: int = 8000) -> Optional[str]:
encodings = ['utf-8', 'gbk', 'gb2312', 'gb18030', 'big5', 'latin-1']
for enc in encodings:
try:
with open(file_path, 'r', encoding=enc) as f:
return f.read(max_chars)
except:
continue
return None
def _build_pools(self):
print("📚 正在构建语料精华池...")
file_paths = []
for base_dir in self.target_dirs:
if not os.path.exists(base_dir):
continue
for root, dirs, files in os.walk(base_dir):
for file in files:
if file.endswith(('.txt', '.md', '.json', '.csv')):
file_paths.append(os.path.join(root, file))
self.total_files = len(file_paths)
print(f" 发现 {self.total_files} 个文件")
random.shuffle(file_paths)
for idx, file_path in enumerate(file_paths):
content = self._read_file_with_fallback(file_path, 8000)
if content is None:
continue
try:
self.all_chars.extend([ch for ch in content if ch.isprintable()])
sentences = re.findall(r'[^。!?;]*[。!?;]', content)
self.sentence_pool.extend([s.strip() for s in sentences if 5 < len(s.strip()) < 100])
self.scanned_count += 1
if self.scanned_count % 100 == 0:
print(f" 扫描进度: {self.scanned_count}/{self.total_files}")
if len(self.all_chars) > 100000:
self.all_chars = self.all_chars[:100000]
if len(self.sentence_pool) > 2000:
self.sentence_pool = self.sentence_pool[:2000]
except Exception as e:
print(f" ⚠️ 处理失败 {file_path}: {e}")
self.has_scanned_all_files = True
self.sentence_pool = list(set(self.sentence_pool))
print(f" ✅ 精华池构建完成!")
print(f" 已扫描文件: {self.scanned_count}/{self.total_files}")
print(f" 字符量: {len(self.all_chars)}")
print(f" 句子量: {len(self.sentence_pool)}")
if self.scanned_count < self.total_files:
print(f" ⚠️ 部分文件无法解码,已跳过")
def get_char_frequency(self, max_chars: int = 50000) -> Counter:
freq = Counter()
for ch in self.all_chars[:max_chars]:
freq[ch] += 1
return freq
def get_sample_sentences(self, num_sentences: int = 200) -> List[str]:
if not self.sentence_pool:
return []
random.shuffle(self.sentence_pool)
return self.sentence_pool[:num_sentences]
def get_total_text_size(self) -> int:
total = 0
for base_dir in self.target_dirs:
if not os.path.exists(base_dir):
continue
for root, dirs, files in os.walk(base_dir):
for file in files:
if file.endswith(('.txt', '.md', '.json', '.csv')):
try:
total += os.path.getsize(os.path.join(root, file))
except:
pass
return total
# ==================== 火2(从精选池捞单元) ====================
class Huo2(Student):
def __init__(self, corpus_reader: CorpusReader):
super().__init__("2", "火2-化")
self.corpus_reader = corpus_reader
self.char_freq = None
def _build_freq(self):
if self.char_freq is None:
print(f" 📊 [{self.name}] 正在统计语料字符频率...")
self.char_freq = Counter(self.corpus_reader.all_chars)
print(f" 📊 [{self.name}] 统计完成,共 {len(self.char_freq)} 种字符")
def _get_dao_curiosity(self) -> float:
if self.luoshu and hasattr(self.luoshu, 'dao_novelty'):
return self.luoshu.dao_novelty
return 0.5
def _rule_based_execute(self, context: Dict) -> Dict:
self._build_freq()
strategy = self.strategy_net.predict(self.memory[-10:])
dao_curiosity = self._get_dao_curiosity()
curiosity = strategy["curiosity"] * (1.2 - self.skill_level) * (0.5 + dao_curiosity)
high_freq = [ch for ch, cnt in self.char_freq.most_common(80) if ch.isprintable()]
low_freq = [ch for ch, cnt in self.char_freq.items() if cnt <= 3 and ch.isprintable()]
curiosity_count = max(1, min(20, int(len(low_freq) * max(0.1, curiosity))))
curious_picks = random.sample(low_freq, min(curiosity_count, len(low_freq)))
result = list(set(high_freq + curious_picks))[:200]
return {"units": result, "count": len(result)}
# ==================== 木3(从火池捞单元组句子) ====================
class Mu3(Student):
def __init__(self, corpus_reader: CorpusReader):
super().__init__("3", "木3-生")
self.corpus_reader = corpus_reader
self.sentence_pool = []
def _refresh_sentence_pool(self):
if not self.sentence_pool:
print(f" 📖 [{self.name}] 正在收集语料中的句子...")
all_sentences = self.corpus_reader.get_sample_sentences(200)
self.sentence_pool = [s for s in all_sentences if self._is_good_sentence(s)]
print(f" 📖 [{self.name}] 收集到 {len(self.sentence_pool)} 个好句子")
def _is_good_sentence(self, s: str) -> bool:
if len(s) < 10 or len(s) > 100:
return False
if s[-1] not in "。!?;":
return False
chinese_count = sum(1 for c in s if '\u4e00' <= c <= '\u9fff')
if chinese_count / len(s) < 0.6:
return False
if re.search(r'\d{2,}', s):
return False
return True
def _get_dao_length(self) -> float:
if self.luoshu and hasattr(self.luoshu, 'dao_novelty'):
return self.luoshu.dao_novelty
return 0.5
def _rule_based_execute(self, context: Dict) -> Dict:
self._refresh_sentence_pool()
dao_length = self._get_dao_length()
strategy = self.strategy_net.predict(self.memory[-10:])
length = min(40, max(12, int(10 + strategy["intensity"] * 10 + dao_length * 5)))
if self.sentence_pool:
sentence = random.choice(self.sentence_pool).strip()
if len(sentence) > length:
sentence = sentence[:length]
return {"sentence": sentence, "length": len(sentence)}
if self.luoshu and hasattr(self.luoshu, 'fire_pool'):
units = self.luoshu.fire_pool.get_best(50)
if units:
sentence_chars = random.sample(units, min(length, len(units)))
sentence = ''.join(sentence_chars)
return {"sentence": sentence, "length": len(sentence)}
units = context.get("units", [])
if not units:
return {"sentence": "", "length": 0}
sentence_chars = random.sample(units, min(length, len(units)))
sentence = ''.join(sentence_chars)
return {"sentence": sentence, "length": len(sentence)}
# ==================== 水1(二八定律:80%从木池捞主食,20%从火池捞零食) ====================
class Shui1(Student):
def __init__(self, student_id: str, name: str):
super().__init__(student_id, name)
self.source_stats = {"木池": 0, "火池": 0}
def _get_dao_variety(self) -> float:
if self.luoshu and hasattr(self.luoshu, 'dao_novelty'):
return self.luoshu.dao_novelty
return 0.5
def _rule_based_execute(self, context: Dict) -> Dict:
sentence = None
source = None
# 二八定律:80%从木池捞主食,20%从火池捞零食
use_wood_pool = random.random() < 0.8
if use_wood_pool and self.luoshu and hasattr(self.luoshu, 'wood_pool'):
candidates = self.luoshu.wood_pool.get_best(min_len=8, max_len=100, num=5)
if candidates:
sentence = random.choice(candidates)
source = "木池"
print(f" 🌳 [水1] 从木池捞主食: {sentence[:40]}...")
if not sentence and self.luoshu and hasattr(self.luoshu, 'fire_pool'):
# 从火池捞单元,自己组装成句子
units = self.luoshu.fire_pool.get_best(50)
if units:
strategy = self.strategy_net.predict(self.memory[-10:])
dao_variety = self._get_dao_variety()
length = min(40, max(12, int(15 + strategy["intensity"] * 10 + dao_variety * 5)))
sentence_chars = random.sample(units, min(length, len(units)))
sentence = ''.join(sentence_chars)
source = "火池"
print(f" 🔥 [水1] 从火池捞零食(自组装): {sentence[:40]}...")
if not sentence:
sentence = context.get("sentence", "")
source = "原始"
if not sentence or len(sentence) < 8:
return {"variants": [], "original": ""}
strategy = self.strategy_net.predict(self.memory[-10:])
dao_variety = self._get_dao_variety()
variety = strategy["variety"] * self.skill_level * (0.5 + dao_variety)
variants = []
variants.append(sentence[::-1])
if len(sentence) > 8:
mid = len(sentence) // 2
variants.append(sentence[mid:] + sentence[:mid])
if len(sentence) > 8:
pos = random.randint(2, len(sentence)-2)
variants.append(sentence[:pos] + " " + sentence[pos:])
if variety > 0.8 and len(sentence) > 8:
chars = list(sentence)
random.shuffle(chars)
variants.append(''.join(chars))
variants = list(set(variants))
# 把变体加入水池
if self.luoshu and hasattr(self.luoshu, 'water_pool'):
for v in variants:
self.luoshu.water_pool.add(v, source="水1", score=0.5)
if source:
self.source_stats[source] = self.source_stats.get(source, 0) + 1
total = sum(self.source_stats.values())
if total % 100 == 0 and total > 0:
wood_ratio = self.source_stats.get("木池", 0) / total * 100
print(f" 📊 [水1] 来源统计: 木池{wood_ratio:.0f}% / 火池{100-wood_ratio:.0f}% (目标80/20)")
return {"variants": variants, "original": sentence}
# ==================== 金4(二八定律:80%从水池捞主食,20%从木池偷零食) ====================
class Jin4(Student):
def __init__(self):
super().__init__("4", "金4-成")
self.works = []
self.source_stats = {"水池": 0, "木池": 0, "原始": 0}
def _get_golden_subdir(self) -> str:
subdir_num = (self.luoshu.system.round // 1000) if self.luoshu and hasattr(self.luoshu, 'system') else 0
return f"golden_works/round_{subdir_num*1000}_{(subdir_num+1)*1000-1}"
def _save_golden_work(self, work: str):
golden_base = "golden_works"
subdir = self._get_golden_subdir()
golden_dir = os.path.join(golden_base, subdir)
os.makedirs(golden_dir, exist_ok=True)
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
safe_title = re.sub(r'[\\/*?:"<>|\n\r\t]', '', work[:30].strip())
safe_title = re.sub(r'\s+', '_', safe_title)
if not safe_title:
safe_title = "unnamed"
filename = f"{golden_dir}/{timestamp}_{safe_title}.txt"
tmp_filename = filename + ".tmp"
try:
with open(tmp_filename, 'w', encoding='utf-8') as f:
f.write(f"# 固化时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}\n")
f.write(f"# 作品长度: {len(work)} 字符\n")
f.write("="*60 + "\n\n")
f.write(work)
f.write("\n\n" + "="*60 + "\n")
os.replace(tmp_filename, filename)
print(f" 💎 金作品已保存: {filename}")
except Exception as e:
print(f" ⚠️ 保存金作品失败: {e}")
def _get_dao_threshold(self) -> float:
if self.luoshu and hasattr(self.luoshu, 'dao_novelty'):
return (self.luoshu.dao_novelty - 0.5) * 0.2
return 0.0
def _rule_based_execute(self, context: Dict) -> Dict:
teacher9_threshold = context.get("teacher9_threshold", 0.6)
best = None
source = None
# 二八定律:80%从水池捞主食,20%从木池偷零食
use_water_pool = random.random() < 0.8
if use_water_pool and self.luoshu and hasattr(self.luoshu, 'water_pool'):
candidates = self.luoshu.water_pool.get_best(
min_len=12, max_len=100,
exclude=set(self.works), num=1
)
if candidates:
best = candidates[0]
source = "水池"
print(f" 💧 [金4] 从水池捞主食: {best[:40]}...")
if not best and self.luoshu and hasattr(self.luoshu, 'wood_pool'):
candidates = self.luoshu.wood_pool.get_best(min_len=12, max_len=100, num=5)
if candidates:
best = random.choice(candidates)
source = "木池"
print(f" 🌳 [金4] 从木池偷零食: {best[:40]}...")
if not best:
original_sentence = context.get("original_sentence", "")
if original_sentence and 12 <= len(original_sentence) <= 100:
if any('\u4e00' <= c <= '\u9fff' for c in original_sentence):
best = original_sentence
source = "原始"
print(f" 🎣 [金4] 从木3原始句子兜底: {best[:40]}...")
if not best:
return {"final": "", "works_count": len(self.works)}
dao_effect = self._get_dao_threshold()
strategy = self.strategy_net.predict(self.memory[-10:])
dynamic_threshold = teacher9_threshold + strategy["intensity"] * 0.1 - self.skill_level * 0.1 + dao_effect
dynamic_threshold = max(0.3, min(0.95, dynamic_threshold))
if random.random() > dynamic_threshold:
self.works.append(best)
self._save_golden_work(best)
if self.luoshu:
self.luoshu.add_masterpiece(best, "金4")
if source:
self.source_stats[source] = self.source_stats.get(source, 0) + 1
total = sum(self.source_stats.values())
if total % 100 == 0 and total > 0:
water_ratio = self.source_stats.get("水池", 0) / total * 100
wood_ratio = self.source_stats.get("木池", 0) / total * 100
print(f" 📊 [金4] 来源统计: 水池{water_ratio:.0f}% / 木池{wood_ratio:.0f}% (目标80/20)")
print(f" ✅ 固化作品 ({source}): {best[:50]}... (阈值={dynamic_threshold:.2f})")
return {"final": best, "works_count": len(self.works)}
print(f" ⏸️ 未固化新作品 (阈值={dynamic_threshold:.2f})")
return {"final": "", "works_count": len(self.works)}
# ==================== 主系统 ====================
class HeTuLuoShuSystem:
def __init__(self):
print("🐉 河图洛书智能体 - V4(镜像+圆周率+二八定律)")
print(" 镜像层:四池架构 + 五行生克 + 阴阳平衡")
print(" 道层:真圆周率引擎(gmpy2),流式加载,永不枯竭")
print(" 数据流向:")
print(" 精选池 → 火2 → 火池(提取单元)")
print(" 火池 → 木3 → 木池(组句子)")
print(" 木池(80%) + 火池(20%) → 水1 → 水池(变花样)")
print(" 水池(80%) + 木池(20%) → 金4 → 金池(固化作品)")
print(" 二八定律:")
print(" 水1: 80%从木池捞主食,20%从火池捞零食自组装")
print(" 金4: 80%从水池捞主食,20%从木池偷零食")
print("="*60)
target_dirs = ["corpus", "learning_material", "novels", "self_grown"]
self.corpus_reader = CorpusReader(target_dirs)
self.crawler_lock = False
self.huo2 = Huo2(self.corpus_reader)
self.mu3 = Mu3(self.corpus_reader)
self.shui1 = Shui1("1", "水1-变")
self.jin4 = Jin4()
self.jin4.luoshu = type('obj', (object,), {'system': self, 'common_memory': {}})()
self.students = {"火2": self.huo2, "木3": self.mu3, "水1": self.shui1, "金4": self.jin4}
self.teachers = {
"7": Teacher("7", "火2"),
"8": Teacher("8", "木3"),
"6": Teacher("6", "水1"),
"9": Teacher("9", "金4")
}
self.luoshu = LuoShuCenter()
self.luoshu.synonym_learner = self.luoshu.synonym_learner
self.luoshu.fire_pool = self.luoshu.fire_pool
self.luoshu.wood_pool = self.luoshu.wood_pool
self.luoshu.water_pool = self.luoshu.water_pool
for s in self.students.values():
s.luoshu = self.luoshu
for t in self.teachers.values():
t.luoshu = self.luoshu
self.jin4.luoshu = self.luoshu
self.luoshu.refresh_fire_pool_from_corpus(self)
self.round = 0
self.masterpiece_round = 0
self._load_global_memory()
self.output_dir = "masterpieces"
os.makedirs(self.output_dir, exist_ok=True)
os.makedirs("standards", exist_ok=True)
os.makedirs("golden_works", exist_ok=True)
os.makedirs("memories", exist_ok=True)
for tid, teacher in self.teachers.items():
teacher._save_standard(0)
self._ensure_initial_corpus()
def _ensure_initial_corpus(self):
total_size = self.corpus_reader.get_total_text_size()
if total_size < 10000:
print(f"\n⚠️ 投喂语料不足({total_size}字节),触发初始爬取...")
self._ensure_corpus_sufficient()
def _atomic_write(self, filename: str, data: dict):
tmp_filename = filename + ".tmp"
with open(tmp_filename, 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=2)
os.replace(tmp_filename, filename)
def get_crawler_size(self) -> int:
try:
result = subprocess.run(
["python", "smart_crawler.py", "status"],
capture_output=True, text=True, timeout=10
)
if result.returncode == 0:
data = json.loads(result.stdout)
return data.get("total_size", 0)
except Exception as e:
print(f"⚠️ 获取爬虫状态失败: {e}")
return 0
def _check_and_recover_teachers(self):
for tid, teacher in self.teachers.items():
teacher.try_recover()
def _ensure_corpus_sufficient(self):
if self.crawler_lock:
return
lock_file = "self_grown/crawler.lock"
if os.path.exists(lock_file):
try:
mtime = os.path.getmtime(lock_file)
if time.time() - mtime < 600:
print(f"⚠️ 爬虫正在运行,跳过本次检查")
return
else:
os.remove(lock_file)
except:
pass
current_stage = self.luoshu.common_memory["stage"]
current_size = self.get_crawler_size()
if current_stage == "小学":
target_size = int(self.corpus_reader.get_total_text_size() * 0.9)
if current_size < target_size:
print(f"\n⚠️ 洛书中心:语料不足,启动独立爬虫进程")
print(f" 当前语料: {current_size} 字节")
print(f" 目标语料: {target_size} 字节")
self.crawler_lock = True
result = subprocess.run(
["python", "smart_crawler.py", "fetch", str(target_size)],
capture_output=True, text=True, timeout=300
)
self.crawler_lock = False
if result.returncode == 0:
print(f"✅ 爬虫完成,语料已更新")
self.luoshu.refresh_fire_pool_from_corpus(self)
else:
print(f"⚠️ 爬虫执行失败: {result.stderr}")
elif current_stage in ["中学", "大学"]:
target_size = self.corpus_reader.get_total_text_size() * (3 if current_stage == "中学" else 9)
if current_size < target_size:
print(f"\n⚠️ 洛书中心:{current_stage}阶段语料不足,启动爬虫")
self.crawler_lock = True
subprocess.run(["python", "smart_crawler.py", "fetch", str(target_size)], timeout=600)
self.crawler_lock = False
self.luoshu.refresh_fire_pool_from_corpus(self)
def _get_global_filename(self) -> str:
return "memory_snapshot.json"
def _save_global_memory(self):
memory_data = {
"round": self.round,
"masterpiece_round": self.masterpiece_round,
"common_memory": self.luoshu.common_memory,
"teachers": {
tid: {
"pass_threshold": t.pass_threshold,
"rule_description": t.rule_description,
"use_fallback": t.use_fallback
} for tid, t in self.teachers.items()
}
}
self._atomic_write(self._get_global_filename(), memory_data)
def _load_global_memory(self):
filename = self._get_global_filename()
if os.path.exists(filename):
try:
with open(filename, 'r', encoding='utf-8') as f:
data = json.load(f)
self.round = data.get("round", 0)
self.masterpiece_round = data.get("masterpiece_round", 0)
self.luoshu.common_memory = data.get("common_memory", self.luoshu.common_memory)
for tid, tdata in data.get("teachers", {}).items():
if tid in self.teachers:
self.teachers[tid].pass_threshold = tdata.get("pass_threshold", 0.6)
self.teachers[tid].rule_description = tdata.get("rule_description", self.teachers[tid].rule_description)
self.teachers[tid].use_fallback = tdata.get("use_fallback", False)
print(f"📂 恢复全局记忆,从第 {self.round} 轮继续")
except Exception as e:
print(f"⚠️ 加载全局记忆失败: {e}")
def _save_masterpiece(self):
if self.round - self.masterpiece_round >= 100 and self.round > 0:
self.masterpiece_round = self.round
if self.jin4.works:
latest = self.jin4.works[-1]
filename = f"{self.output_dir}/masterpiece_{self.round:06d}.txt"
tmp_filename = filename + ".tmp"
with open(tmp_filename, 'w', encoding='utf-8') as f:
f.write(f"# 河图洛书智能体 - 第{self.round}轮作品\n")
f.write(f"# 时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}\n")
f.write(f"# 当前阶段: {self.luoshu.common_memory['stage']}\n")
f.write(f"# 道已计算: {self.luoshu.dao.get_pointer()} 位圆周率\n")
f.write(f"# 作品长度: {len(latest)} 字符\n")
f.write("="*60 + "\n\n")
f.write(latest)
f.write("\n\n" + "="*60 + "\n")
os.replace(tmp_filename, filename)
print(f"\n📖 已保存作品: {filename}\n")
else:
filename = f"{self.output_dir}/masterpiece_{self.round:06d}_none.txt"
with open(filename, 'w', encoding='utf-8') as f:
f.write(f"# 河图洛书智能体 - 第{self.round}轮无新作品\n")
f.write(f"# 时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}\n")
f.write(f"# 道已计算: {self.luoshu.dao.get_pointer()} 位圆周率\n")
print(f"\n📖 第{self.round}轮无新作品\n")
def _get_learning_topic(self, student_name: str) -> str:
topics = {
"火2-化": "中文文本特征提取和关键词抽取方法",
"木3-生": "如何生成通顺、有意义的完整中文句子",
"水1-变": "中文句子的变形技巧:反转、移位、重组",
"金4-成": "优秀文学作品的评判标准和语言艺术"
}
return topics.get(student_name, "中文语言学习")
def _run_student(self, student, teacher, prev_output=None):
student_name = student.name
if student.blocked:
print(f" 🚫 [{student_name}] 阻塞中,学习轮次: {student.learning_rounds}/3")
if student.can_retry():
print(f" 🔓 [{student_name}] 已解封,开始执行")
else:
topic = self._get_learning_topic(student_name)
student.learn(topic)
return None, False
context = {}
if student_name == "木3-生" and prev_output:
context["units"] = prev_output.get("units", [])
elif student_name == "水1-变" and prev_output:
context["sentence"] = prev_output.get("sentence", "")
elif student_name == "金4-成" and prev_output:
context["variants"] = prev_output.get("variants", [])
context["original_sentence"] = prev_output.get("sentence", "")
context["teacher9_threshold"] = teacher.pass_threshold
output = student.execute(context)
passed, score, comment = teacher.evaluate(output)
student.receive_feedback(score, comment)
self.luoshu.report(student_name.split("-")[0], score, passed)
print(f" 📋 老师{teacher.id}: {'✅通过' if passed else '❌不通过'} (分:{score:.2f}) {comment}")
if passed:
student.on_pass()
if student_name == "火2-化":
for unit in output.get("units", []):
self.luoshu.fire_pool.add(unit, source="火2", frequency=1, quality=0.5)
elif student_name == "木3-生":
sentence = output.get("sentence", "")
if sentence:
self.luoshu.wood_pool.add(sentence, source="木3", score=score)
elif student_name == "水1-变":
for variant in output.get("variants", []):
self.luoshu.water_pool.add(variant, source="水1", score=0.5)
else:
student.on_fail(comment)
return output, passed
def run_one_round(self):
self.round += 1
print(f"\n{'='*60}")
print(f"第 {self.round} 轮")
print(f"阶段: {self.luoshu.common_memory['stage']}")
print(f"道已计算: {self.luoshu.dao.get_pointer()} 位圆周率")
print(f" 火2毕业: {self.huo2.is_graduated} | 木3毕业: {self.mu3.is_graduated} | 水1毕业: {self.shui1.is_graduated} | 金4毕业: {self.jin4.is_graduated}")
output = None
output, passed = self._run_student(self.huo2, self.teachers["7"])
if not self.huo2.is_graduated:
self._save_global_memory()
return
output, passed = self._run_student(self.mu3, self.teachers["8"], output)
if not self.mu3.is_graduated:
self._save_global_memory()
return
output, passed = self._run_student(self.shui1, self.teachers["6"], output)
if not self.shui1.is_graduated:
self._save_global_memory()
return
output, passed = self._run_student(self.jin4, self.teachers["9"], output)
if self.round % 100 == 0 and self.round > 0:
print(f"\n{'='*40}")
print("【系统进化】")
for tid, teacher in self.teachers.items():
teacher.self_evolve(self.round)
time.sleep(0.5)
self.luoshu.self_evolve(self)
self.luoshu.update_weights_and_stage(self)
self._check_and_recover_teachers()
self._ensure_corpus_sufficient()
print("="*40)
if self.round % 50 == 0:
stats = self.luoshu.get_pool_stats()
print(f"\n📊 统计: 金池 {stats['masterpieces']} | 金4作品 {len(self.jin4.works)}")
print(f" 火池: {stats['fire_pool']['size']}/{stats['fire_pool']['max']}")
print(f" 木池: {stats['wood_pool']['size']}/{stats['wood_pool']['max']}")
print(f" 水池: {stats['water_pool']['size']}/{stats['water_pool']['max']}")
print(f" 道: 已计算 {stats['dao_pointer']} 位圆周率")
self._save_global_memory()
self._save_masterpiece()
def run_forever(self):
print("\n🚀 进入永久学习模式...")
print(" 数据流向:精选池→火2→火池→木3→木池→水1→水池→金4→金池")
print(" 道层:真圆周率(gmpy2),流式加载,永不枯竭")
print(" 二八定律:")
print(" 水1: 80%从木池捞主食,20%从火池捞零食自组装")
print(" 金4: 80%从水池捞主食,20%从木池偷零食")
print(" Ctrl+C 可安全中断,状态自动保存\n")
try:
while True:
self.run_one_round()
time.sleep(0.2)
except KeyboardInterrupt:
print("\n\n⚠️ 用户中断,状态已保存")
print(f" 当前轮数: {self.round}")
print(f" 金4作品数: {len(self.jin4.works)}")
print(f" 道已计算: {self.luoshu.dao.get_pointer()} 位圆周率")
self._save_global_memory()
for s in self.students.values():
s._save_individual_memory()
for t in self.teachers.values():
t._save_individual_memory()
self.luoshu._save_individual_memory()
print(" 下次运行将从中断处继续")
print("\n🐉 河图洛书智能体 V4 已休眠")
if __name__ == "__main__":
system = HeTuLuoShuSystem()
system.run_forever()
|